Compressing TCP/IP Headers for Low-Speed Serial Links (RFC 1144)
Posted on |
Compressing TCP/IP Headers for Low-Speed Serial Links
(RFC 1144)
1 Introduction
As increasingly powerful computers find their way into people’s homes, there is growing interest in extending Internet connectivity to those computers. Unfortunately, this extension exposes some complex problems in link-level framing, address assignment, routing, authentication, and performance. As of this writing, there is active work in all these areas. This memo describes a method that has been used to improve TCP/IP performance over low speed (300 to 19,200 bps) serial links.
The compression proposed here is similar in spirit to the Thinwire-II protocol described in [5]. However, this protocol compresses more effectively (the average compressed header is 3 bytes compared to 13 in Thinwire-II) and is both efficient and simple to implement (the Unix implementation is 250 lines of C and requires, on the average, 90_s (_170 instructions) for a 20MHz MC68020 to compress or decompress a packet).
This compression is specific to TCP/IP datagrams. The author investigated compressing UDP/IP datagrams but found that they were too infrequent to be worth the bother and either there was insufficient datagram-to-datagram coherence for good compression (e.g., name server queries) or the higher level protocol headers overwhelmed the cost of the UDP/IP header (e.g., Sun’s RPC/NFS). Separately compressing the IP and the TCP portions of the datagram were also investigated but rejected since it increased the average compressed header size by 50% and doubled the compression and decompression code size.
2 The problem
Internet services one might wish to access over a serial IP link from home range from interactive “terminal” type connections (e.g., telnet, rlogin, xterm) to bulk data transfer (e.g., ftp, smtp, nntp). Header compression is motivated by the need for a good interactive response. I.e., the line efficiency of a protocol is the ratio of the data to header+data in a datagram. If an efficient bulk data transfer is the only objective, it is always possible to make the datagram large enough to approach an efficiency of 100%.
Human-factors studies[15] have found that interactive response is perceived as “bad” when low-level feedback (character echo) takes longer than 100 to 200 ms. Protocol headers interact with this threshold three ways:
From the above, it’s clear that one design goal of the compression should be to limit the bandwidth demand of typing and ack traffic to at most 300 bps. A typical maximum typing speed is around five characters per second which leaves a budget 30 – 5 = 25 characters for headers or five bytes of header per character typed. Five-byte headers solve problems (1) and (3) directly and, indirectly, problem (2): A packet size of 100–200 bytes will easily amortize the cost of a five-byte header and offer a user 95–98% of the line bandwidth for data. These short packets mean little interference between interactive and bulk data traffic (see sec. 5.2).
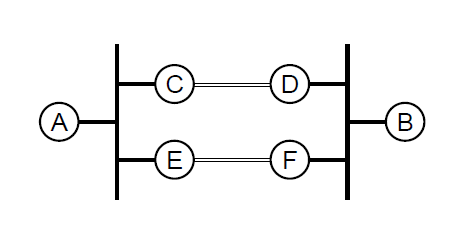
Another design goal is that the compression protocol be based solely on information guaranteed to be known to both ends of a single serial link. Consider the topology shown in fig. 1 where communicating hosts A and B are on separate local area nets (the heavy black lines) and the nets are connected by two serial links (the open lines between gateways C–D and E–F). One compression possibility would be to convert each TCP/IP conversation into a semantically equivalent conversation in a protocol with smaller headers, e.g., to an X.25 call. But, because of routing transients or multipathing, it’s entirely possible that some of the A–B traffic will follow the A – C – D – B path and some will follow the A – E – F – B path. Similarly, it’s possible that A=>B traffic will flow A-C-D-B and B=>A traffic will flow B – F – E – A. None of the gateways can count on seeing all the packets in a particular TCP conversation and a compression algorithm that works for such a topology cannot be tied to the TCP connection syntax.
A physical link treated as two, independent, simplex links (one each direction) imposes the minimum requirements on topology, routing and pipelining. The ends of each simplex link only have to agree on the most recent packet(s) sent on that link. Thus, although any compression scheme involves shared state, this state is spatially and temporally local and adheres to Dave Clark’s principle of fate sharing: The two ends can only disagree on the state if the link connecting them is inoperable, in which case the disagreement doesn’t matter.
3 The compression algorithm
The basic idea
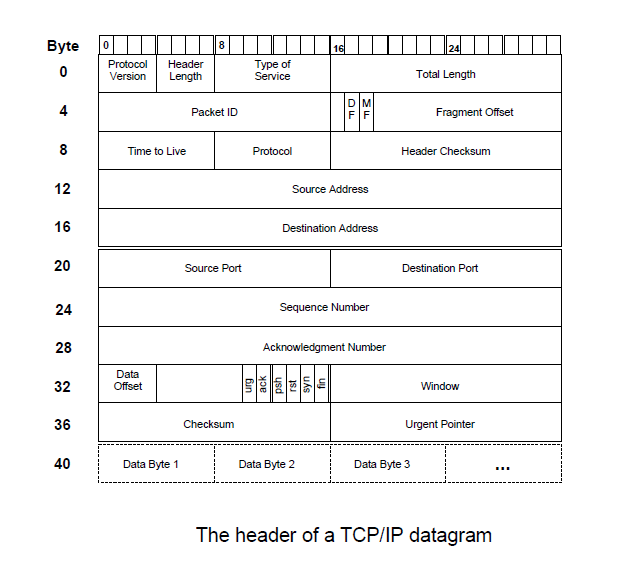
Figure 2 shows a typical (and minimum length) TCP/IP datagram header. The header size is 40 bytes: 20 bytes of IP and 20 of TCP. Unfortunately, since the TCP and IP protocols were not designed by a committee, all these header fields serve some useful purpose and it’s not possible to simply omit some in the name of efficiency.
However, TCP establishes connections and, typically, tens or hundreds of packets are exchanged on each connection. How much of the per-packet information is likely to stay constant over the life of a connection? Half—the shaded fields in fig. 3. So, if the sender and receiver keep track of active connections7 and the receiver keeps a copy of the header from the last packet it saw from each connection, the sender gets a factor-of-two compression by sending only a small (_8 bit) connection identifier together with the 20 bytes that change and letting the receiver fill in the 20 fixed bytes from the saved header.
One can scavenge a few more bytes by noting that any reasonable link-level framing protocol will tell the receiver the length of a received message so total length (bytes 2 and 3) is redundant. But then the header checksum (bytes 10 and 11), which protects individual hops from processing a corrupted IP header, is essentially the only part of the IP header being sent. It seems rather silly to protect the transmission of information that isn’t being transmitted. So, the receiver can check the header checksum when the header is actually sent (i.e., in an uncompressed datagram) but, for compressed datagrams, regenerate it locally at the same time the rest of the IP header is being regenerated.

This leaves 16 bytes of header information to send. All of these bytes are likely to change over the life of the conversation but they do not all change at the same time. For example, during an FTP data transfer only the packet ID, sequence number and checksum change in the sender!receiver direction and only the packet ID, ack, checksum and, possibly, window, change in the receiver!sender direction. With a copy of the last packet sent for each connection, the sender can figure out what fields change in the current packet then send a bitmask indicating what changed followed by the changing fields.
If the sender only sends fields that differ, the above scheme gets the average header size down to around ten bytes. However, it’s worthwhile looking at how the fields change: The packet ID typically comes from a counter that is incremented by one for each packet sent. I.e., the difference between the current and previous packet IDs should be a small, positive integer, usually <256 (one byte) and frequently =1. For packets from the sender side of a data transfer, the sequence number in the current packet will be the sequence number in the previous packet plus the amount of data in the previous packet (assuming the packets are arriving in order). Since IP packets can be at most 64K, the sequence number change must be <216 (two bytes). So, if the differences in the changing fields are sent rather than the fields themselves, another three or four bytes per packet can be saved.
That gets us to the five-byte header target. Recognizing a couple of special cases will get us three-byte headers for the two most common cases—interactive typing traffic and bulk data transfer—but the basic compression scheme is the differential coding developed above. Given that this intellectual exercise suggests it is possible to get five-byte headers, it seems reasonable to flesh out the missing details and actually implement something.
The ugly details
Overview
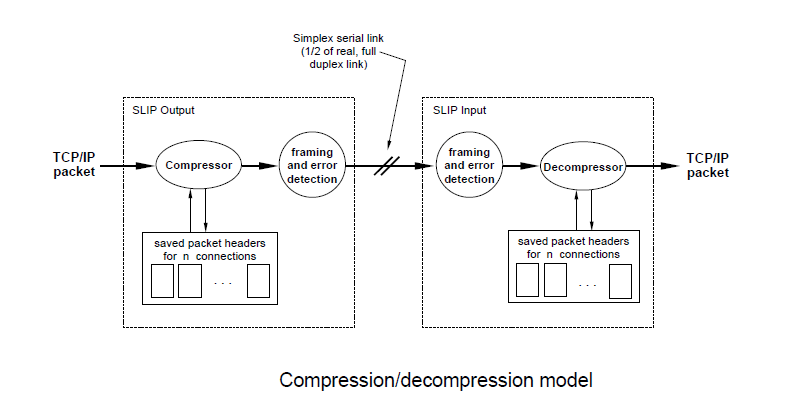
Figure 4 shows a block diagram of the compression software. The networking system calls a SLIP output driver with an IP packet to be sent over the serial line. The packet goes through a compressor which checks if the protocol is TCP. Non-TCP packets and “uncompressible” TCP packets (described below) are just marked as TYPE IP and passed to a framer. Compressible TCP packets are looked up in an array of packet headers. If a matching connection is found, the incoming packet is compressed, the (uncompressed) packet header is copied into the array, and a packet of type COMPRESSED TCP is sent to the framer. If no match is found, the oldest entry in the array is discarded, the packet header is copied into that slot, and a packet of type UNCOMPRESSED TCP is sent to the framer. (An UNCOMPRESSED TCP packet is identical to the original IP packet except the IP protocol field is replaced with a connection number—an index into the array of saved, per-connection packet headers. This is how the sender (re-)synchronizes the receiver and “seeds” it with the first, uncompressed packet of a compressed packet sequence.)
The framer is responsible for communicating the packet data, type and boundary (so the decompressor can learn how many bytes came out of the compressor). Since the compression is a differential coding, the framer must not re-order packets (this is rarely a concern over a single serial link). It must also provide good error detection and, if connection numbers are compressed, must provide an error indication to the decompressor (see sec. 4). The decompressor does a ‘switch’ on the type of incoming packets: For TYPE IP, the packet is simply passed through. For UNCOMPRESSED TCP, the connection number is extracted from the IP protocol field and IPPROTO TCP is restored, then the connection number is used as an index into the receiver’s array of saved TCP/IP headers and the header of the incoming packet is copied into the indexed slot. For COMPRESSED TCP, the connection number is used as an array index to get the TCP/IP header of the last packet from that connection, the info in the compressed packet is used to update that header, then a new packet is constructed containing the now-current header from the array concatenated with the data from the compressed packet.
Note that the communication is simplex—no information flows in the decompressor to- compressor direction. In particular, this implies that the decompressor is relying on TCP retransmissions to correct the saved state in the event of line errors (see sec. 4).
Compressed packet format
Figure 5 shows the format of a compressed TCP/IP packet. There is a change mask that identifies which of the fields expected to change per-packet actually changed, a connection number so the receiver can locate the saved copy of the last packet for this TCP connection, the unmodified TCP checksum so the end-to-end data integrity check will still be valid, then for each bit set in the change mask, the amount the associated field changed. (Optional fields, controlled by the mask, are enclosed in dashed lines in the figure.) In all cases, the bit is set if the associated field is present and clear if the field is absent.

Since the delta’s in the sequence number, etc., are usually small, particularly if the tuning guidelines in section 5 are followed, all the numbers are encoded in a variable length scheme that, in practice, handles most traffic with eight bits: A change of one through 255 is represented in one byte. Zero is improbable (a change of zero is never sent) so a byte of zero signals an extension: The next two bytes are the MSB and LSB, respectively, of a 16 bit value. Numbers larger than 16 bits force an uncompressed packet to be sent. For example, decimal 15 is encoded as hex 0f, 255 as ff, 65534 as 00fffe, and zero as 00 00 00. This scheme packs and decodes fairly efficiently: The usual case for both encode and decode executes three instructions on an MC680x0.
The numbers sent for TCP sequence number and ack are the difference12 between the current value and the value in the previous packet (an uncompressed packet is sent if the difference is negative or more than 64K). The number sent for the window is also the difference between the current and previous values. However, either positive or negative changes are allowed since the window is a 16 bit field. The packet’s urgent pointer is sent if URG is set (an uncompressed packet is sent if the urgent pointer changes but URG is not set). For packet ID, the number sent is the difference between the current and previous values. However, unlike the rest of the compressed fields, the assumed change when I is clear is one, not zero.
There are two important special cases:
(1) The sequence number and ack both change by the amount of data in the last packet; no window change or URG.
(2) The sequence number changes by the amount of data in the last packet, no ack or window change or URG.
(1) is the case for echoed terminal traffic.
(2) is the sender side of non-echoed terminal traffic or a unidirectional data transfer. Certain combinations of the S, A, W and U bits of the change mask are used to signal these special cases. ‘U’ (urgent data) is rare so two unlikely combinations are SWU (used for case 1) and S AWU (used for case 2). To avoid ambiguity, an uncompressed packet is sent if the actual changes in a packet are S * W U.
Since the ‘active’ connection changes rarely (e.g., a user will type for several minutes in a telnet window before changing to a different window), the C bit allows the connection number to be elided. If C is clear, the connection is assumed to be the same as for the last compressed or uncompressed packet. If C is set, the connection number is in the byte immediately following the change mask.
From the above, it’s probably obvious that compressed terminal traffic usually looks like (in hex): 0B c c d, where the 0B indicates case (1), c c is the two byte TCP checksum and d is the character typed. Commands to vi or emacs, or packets in the data transfer direction of an FTP ‘put’ or ‘get’ look like 0F c c d . . . , and acks for that FTP look like 04 c c a where a is the amount of data being acked.
Compressor processing
The compressor is called with the IP packet to be processed and the compression state structure for the outgoing serial line. It returns a packet ready for final framing and the link level ‘type’ of that packet.
As the last section noted, the compressor converts every input packet into either a TYPE IP, UNCOMPRESSED TCP or COMPRESSED TCP packet. A TYPE IP packet is an unmodified copy15 of the input packet and processing it doesn’t change the compressor’s state in any way.
An UNCOMPRESSED TCP packet is identical to the input packet except the IP protocol field (byte 9) is changed from ‘6’ (protocol TCP) to a connection number. In addition, the state slot associated with the connection number is updated with a copy of the input packet’s IP and TCP headers and the connection number is recorded as the last connection sent on this serial line (for the C compression described below).
A COMPRESSED TCP packet contains the data, if any, from the original packet but the IP and TCP headers are completely replaced with a new, compressed header. The connection state slot and last connection sent are updated by the input packet exactly as for an UNCOMPRESSED TCP packet.
· If the packet is not protocol TCP, send it as TYPE IP.
· If the packet is an IP fragment (i.e., either the fragment offset field is non-zero or the more fragments bit is set), send it as TYPE IP.16
· If any of the TCP control bits SYN, FIN or RST are set or if the ACK bit is clear, consider the packet uncompressible and send it as TYPE IP.
If a packet makes it through the above checks, it will be sent as either UNCOMPRESSED TCP or COMPRESSED TCP:
· If no connection state can be found that matches the packet’s source and destination IP addresses and TCP ports, some state is reclaimed (which should probably be the least recently used) and an UNCOMPRESSED TCP packet is sent.
· If a connection state is found, the packet header it contains is checked against the current packet to make sure there were no unexpected changes. (E.g., that all the shaded fields in fig. 3 are the same). The IP protocol, fragment offset, more fragments, SYN, FIN and RST fields were checked above and the source and destination address and ports were checked as part of locating the state. So the remaining fields to check are protocol version, header length, type of service, don’t fragment, time-to-live, data offset, IP options (if any) and TCP options (if any). If any of these fields differ between the two headers, an UNCOMPRESSED TCP packet is sent.
If all the “unchanging” fields match, an attempt is made to compress the current packet:
· If the URG flag is set, the urgent data field is encoded (note that it may be zero) and the U bit is set in the change mask. Unfortunately, if URG is clear, the urgent data field must be checked against the previous packet and, if it changes, an UNCOMPRESSED TCP packet is sent. (‘Urgent data’ shouldn’t change when URG is clear but [11] doesn’t require this.)
· _ The difference between the current and previous packet’s window field is computed and, if non-zero, is encoded and the W bit is set in the change mask.
· _ The difference between ack fields is computed. If the result is less than zero or greater than 216– 1, an UNCOMPRESSED TCP packet is sent.18 Otherwise, if the result is non-zero, it is encoded and the A bit is set in the change mask.
· _ The difference between sequence number fields is computed. If the result is less than zero or greater than 216 – 1, an UNCOMPRESSED TCP packet is sent.19 Otherwise, if the result is non-zero, it is encoded and the S bit is set in the change mask.
Once the U, W, A and S changes have been determined, the special-case encodings can be checked:
· If U, S and W are set, the changes match one of the special-case encodings. Send an UNCOMPRESSED TCP packet.
· If only S is set, check if the change equals the amount of user data in the last packet. I.e., subtract the TCP and IP header lengths from the last packet’s total length field and compare the result to the S change. If they’re the same, set the change mask to SAWU (the special case for “unidirectional data transfer”) and discard the encoded sequence number change (the decompressor can reconstruct it since it knows the last packet’s total length and header length).
· If only S and A are set, check if they both changed by the same amount and that amount is the amount of user data in the last packet. If so, set the change mask to SWU (the special case for “echoed interactive” traffic) and discard the encoded changes.
· If nothing changed, check if this packet has no user data (in which case it is probably a duplicate ack or window probe) or if the previous packet contained user data (which means this packet is a retransmission on a connection with no pipelining). In either of these cases, send an UNCOMPRESSED TCP packet.
Finally, the TCP/IP header on the outgoing packet is replaced with a compressed header:
· The change in the packet ID is computed and, if not one,20 the difference is encoded (note that it may be zero or negative) and the I bit is set in the change mask.
· If the PUSH bit is set in the original datagram, the P bit is set in the change mask.
· The TCP and IP headers of the packet are copied to the connection state slot.
· The TCP and IP headers of the packet are discarded and a new header is prepended consisting of (in reverse order):
o the accumulated, encoded changes.
o the TCP checksum (if the new header is being constructed “in place”, the checksum may have been overwritten and will have to be taken from the header copy in the connection state or saved in a temporary before the original header is discarded).
o the connection number (if different than the last one sent on this serial line). This also means that the line’s last connection sent must be set to the connection number and the C bit set in the change mask.
o the change mask.
At this point, the compressed TCP packet is passed to the framer for transmission.
Decompressor processing
Because of the simplex communication model, processing at the decompressor is much simpler than at the compressor — all the decisions have been made and the decompressor simply does what the compressor has told it to do.
The decompressor is called with the incoming packet,21 the length and type of the packet and the compression state structure for the incoming serial line. A(possibly re-constructed) IP packet will be returned.
The decompressor can receive four types of packet: the three generated by the compressor and a TYPE-ERROR pseudo-packet generated when the receive framer detects an error. The first step is a ‘switch’ on the packet type:
· If the packet is TYPE-ERROR or an unrecognized type, a ‘toss’ flag is set in the state to force COMPRESSED TCP packets to be discarded until one with the C bit set or an UNCOMPRESSED TCP packet arrives. Nothing (a null packet) is returned.
· If the packet is TYPE IP, an unmodified copy of it is returned and the state is not modified.
· If the packet is UNCOMPRESSED TCP, the state index from the IP protocol field is checked.23 If it’s illegal, the toss flag is set and nothing is returned. Otherwise, the toss flag is cleared, the index is copied to the state’s last connection received field, a copy of the input packet is made,24 the TCP protocol number is restored to the IP protocol field, the packet header is copied to the indicated state slot, then the packet copy is returned.
If the packet was not handled above, it is COMPRESSED TCP and a new TCP/IP header has to be synthesized from information in the packet plus the last packet’s header in the state slot. First, the explicit or implicit connection number is used to locate the state slot:
· If the C bit is set in the change mask, the state index is checked. If it’s illegal, the toss flag is set and nothing is returned. Otherwise, last connection received is set to the packet’s state index and the toss flag is cleared.
· If the C bit is clear and the toss flag is set, the packet is ignored and nothing is returned.
At this point, last connection received is the index of the appropriate state slot and the first byte(s) of the compressed packet (the change mask and, possibly, connection index) have been consumed. Since the TCP/IP header in the state slot must end up reflecting the newly arrived packet, it’s simplest to apply the changes from the packet to that header then construct the output packet from that header concatenated with the data from the input packet. (In the following description, ‘saved header’ is used as an abbreviation for ‘the TCP/IP header saved in the state slot’.)
· The next two bytes in the incoming packet are the TCP checksum. They are copied to the saved header.
· If the P bit is set in the change mask, the TCP PUSH bit is set in the saved header. Otherwise, the PUSH bit is cleared.
· If the low order four bits (S, A, W, and U) of the change mask are all set (the ‘unidirectional data’ special case), the amount of user data in the last packet is calculated by subtracting the TCP and IP header lengths from the IP total length in the saved header. That amount is then added to the TCP sequence number in the saved header.
· If S, Wand U are set and A is clear (the ‘terminal traffic’ special case), the amount of user data in the last packet is calculated and added to both the TCP sequence number and ack fields in the saved header.
· Otherwise, the change mask bits are interpreted individually in the order that the compressor set them:
o If the U bit is set, the TCP URG bit is set in the saved header and the next byte(s) of the incoming packet are decoded and stuffed into the TCP Urgent Pointer. If the U bit is clear, the TCP URG bit is cleared.
o If the W bit is set, the next byte(s) of the incoming packet are decoded and added to the TCP window field of the saved header.
o If the A bit is set, the next byte(s) of the incoming packet are decoded and added to the TCP ack field of the saved header.
o If the S bit is set, the next byte(s) of the incoming packet are decoded and added to the TCP sequence number field of the saved header.
· If the I bit is set in the change mask, the next byte(s) of the incoming packet are decoded and added to the IP ID field of the saved packet. Otherwise, one is added to the IP ID.
At this point, all the header information from the incoming packet has been consumed and only data remains. The length of the remaining data is added to the length of the saved IP and TCP headers and the result is put into the saved IP total length field. The saved IP header is now up to date so its checksum is recalculated and stored in the IP checksum field. Finally, an output datagram consisting of the saved header concatenated with the remaining incoming data is constructed and returned.
 |  |  |  |  |  |
