Compressing TCP/IP Headers for Low-Speed Serial Links (RFC1144)
Posted on |
Compressing TCP/IP Headers for Low-Speed Serial Links
(Error Handling) RFC 1144
Error handling
Error detection
In the author’s experience, dial-up connections are particularly prone to data errors. These errors interact with compression in two different ways: First is the local effect of an error in a compressed packet. All error detection is based on redundancy yet compression has squeezed out almost all the redundancy in the TCP and IP headers. In other words, the decompressor will happily turn random line noise into a perfectly valid TCP/IP packet. 25 One could rely on the TCP checksum to detect corrupted compressed packets but, unfortunately, some rather likely errors will not be detected. For example, the TCP checksum will often not detect two single bit errors separated by 16 bits. For a V.32 modem signaling at 2400 baud with 4 bits/baud, any line hit lasting longer than 400_s. would corrupt 16 bits. According to, residential phone line hits of up to 2ms. are likely.
The correct way to deal with this problem is to provide for error detection at the framing level. Since the framing (at least in theory) can be tailored to the characteristics of a particular link, the detection can be as light or heavy-weight as appropriate for that link. Since packet error detection is done at the framing level, the decompressor simply assumes that it will get an indication that the current packet was received with errors. (The decompressor always ignores (discards) a packet with errors. However, the indication is needed to prevent the error being propagated— see below.)
The “discard erroneous packets” policy gives rise to the second interaction of errors and compression. Consider the following conversation:
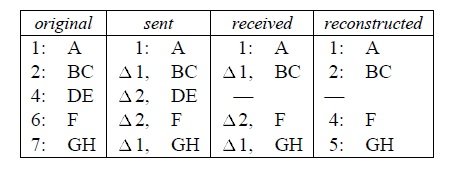
Without some sort of check, the preceding error would result in the receiver invisibly losing two bytes from the middle of the transfer (since the decompressor regenerates sequence numbers, the packets containing F and GH arrive at the receiver’s TCP with exactly the sequence numbers they would have had if the DE packet had never existed). Although some TCP conversations can survive missing data28 it is not a practice to be encouraged. Fortunately, the TCP checksum, since it is a simple sum of the packet contents including the sequence numbers, detects 100% of these errors. E.g., the receiver’s computed checksum for the last two packets above always differs from the packet checksum by two.
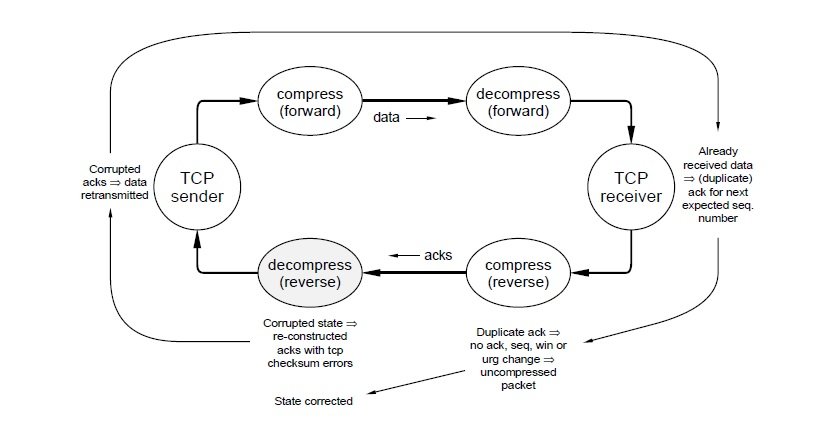
Unfortunately, there is a way for the TCP checksum protection described above to fail if the changes in an incoming compressed packet are applied to the wrong conversation: Consider two active conversations C1 and C2 and a packet from C1 followed by two packets from C2. Since the connection number doesn’t change, it’s omitted from the second C2 packet. But, if the first C2 packet is received with a CRC error, the second C2 packet will mistakenly be considered the next packet inC1. Since the C2 checksum is a random number with respect to the C1 sequence numbers, there is at least a 2-16 probability that this packet will be accepted by the C1 TCP receiver.29 To prevent this, after a CRC error indication
from the framer the receiver discards packets until it receives either a COMPRESSED TCP packet with the C bit set or an UNCOMPRESSED TCP packet. I.e., packets are discarded until the receiver gets an explicit connection number. To summarize this section, there are two different types of errors: per-packet corruption and per-conversation loss-of-sync. The first type is detected at the decompressor from a link-level CRC error, the second at the TCP receiver from a (guaranteed) invalid TCP checksum. The combination of these two independent mechanisms ensures that erroneous packets are discarded.
Error recovery
The previous section noted that after a CRC error the decompressor will introduce TCP checksum errors in every uncompressed packet. Although the checksum errors prevent data stream corruption, the TCP conversation won’t be terribly useful until the decompressor again generates valid packets. How can this be forced to happen?
The decompressor generates invalid packets because its state (the saved ‘last packet header’) disagrees with the compressor’s state. An UNCOMPRESSED TCP packet will correct the decompressor’s state. Thus error recovery amounts to forcing an uncompressed packet out of the compressor whenever the decompressor is (or might be) confused.
The first thought is to take advantage of the full duplex communication link and have the decompressor send something to the compressor requesting an uncompressed packet. This is clearly undesirable since it constrains the topology more than the minimum suggested in sec. 2 and requires that a great deal of protocol be added to both the decompressor and compressor. A little thought convinces one that this alternative is not only undesirable, it simply won’t work: Compressed packets are small and it’s likely that a line hit will so completely obliterate one that the decompressor will get nothing at all. Thus packets are reconstructed incorrectly (because of the missing compressed packet) but only the TCP endpoints, not the decompressor, know that the packets are incorrect.
But the TCP endpoints know about the error and TCP is a reliable protocol designed to run over unreliable media. This means the endpoints must eventually take some sort of error recovery action and there’s an obvious trigger for the compressor to resync the decompressor: send uncompressed packets whenever TCP is doing error recovery.
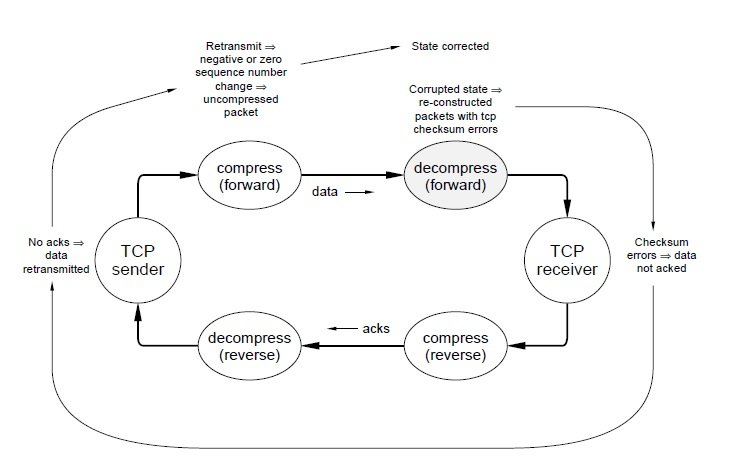
But how does the compressor recognize TCP error recovery? Consider the schematic TCP data transfer of fig. 6. The confused decompressor is in the forward (data transfer) half of the TCP conversation. The receiving TCP discards packets rather than acking them (because of the checksum errors), the sending TCP eventually times out and retransmits a packet, and the forward path compressor finds that the difference between the sequence number in the retransmitted packet and the sequence number in the last packet seen is either negative (if there were multiple packets in transit) or zero (one packet in transit). The first case is detected in the compression step that computes sequence number differences. The second case is detected in the step that checks the ‘special case’ encodings but needs an additional test: It’s fairly common for an interactive conversation to send a dataless ack packet followed by a data packet. The ack and data packet will have the same sequence numbers yet the data packet is not a retransmission. To prevent sending an unnecessary uncompressed packet, the length of the previous packet should be checked and, if it contained data, a zero sequence number change must indicate a retransmission.
Configurable parameters and tuning
Compression configuration
There are two configuration parameters associated with header compression: Whether or not compressed packets should be sent on a particular line and, if so, how many state slots (saved packet headers) to reserve. There is also one link-level configuration parameter, the maximum packet size or MTU, and one front-end configuration parameter, data compression, that interact with header compression. Compression configuration is discussed in this section. MTU and data compression are discussed in the next two sections.
There are some hosts (e.g., low-end PCs) which may not have enough processor or memory resources to implement this compression. There are also rare link or application characteristics that make header compression unnecessary or undesirable. And there are many existing SLIP links that do not currently use this style of header compression. For the sake of interoperability, serial line IP drivers that allow header compression should include some sort of user-configurable flag to disable compression (see Appendix B.2).
If compression is enabled, the compressor must be sure to never send a connection id (state index) that will be dropped by the decompressor. E.g., a black hole is created if the decompressor has sixteen slots and the compressor uses twenty.32 Also, if the compressor is allowed too few slots, the LRU allocator will thrash and most packets will be sent as UNCOMPRESSED TCP. Too many slots and memory is wasted.
Experimenting with different sizes over the past year, the author has found that eight slots will thrash (i.e., the performance degradation is noticeable) when many windows on a multi-window workstation are simultaneously in use or the workstation is being used as a gateway for three or more other machines. Sixteen slots were never observed to thrash. (This may simply be because a 9600 bps line split more than 16 ways is already so overloaded that the additional degradation from round-robbining slots is negligible.)
Each slot must be large enough to hold a maximum length TCP/IP header of 128 bytes so 16 slots occupy 2KB of memory. In these days of 4 Mbit RAM chips, 2KB seems so little memory that the author recommends the following configuration rules:
- If the framing protocol does not allow negotiation, the compressor and decompressor should provide sixteen slots, zero through fifteen.
- If the framing protocol allows negotiation, any mutually agreeable number of slots from 1 to 256 should be negotiable.34 If a number of slots is not negotiated, or until it is negotiated, both sides should assume sixteen.
- If you have complete control of all the machines at both ends of every link and none of them will ever be used to talk to machines outside of your control, you are free to configure them however you please, ignoring the above. However, when your little eastern-block dictatorship collapses (as they all eventually seem to), be aware that a large, vocal, and not particularly forgiving Internet community will take great delight in pointing out to anyone willing to listen that you have misconfigured your systems and are not interoperable.
Choosing a maximum transmission unit
From the discussion in Sec. 2, it seems desirable to limit the maximum packet size (MTU) on any line where there might be interactive traffic and multiple active connections (to maintain good interactive response between the different connections competing for the line). The obvious question is “how much does this hurt throughput?” It doesn’t.
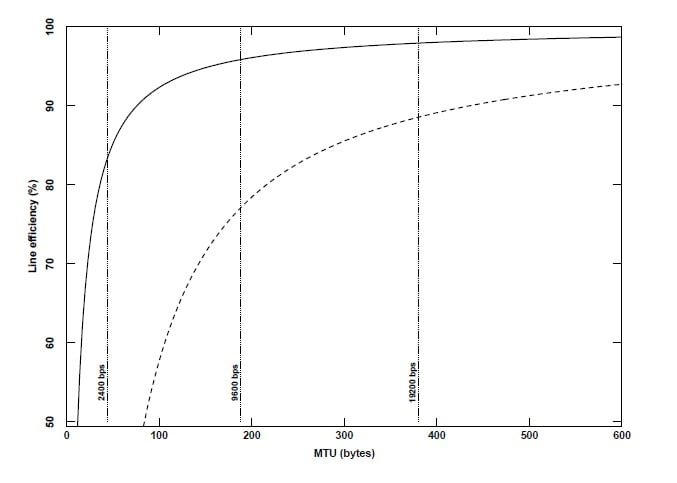
Figure 8 shows how user data throughput35 scales with MTU with (solid line) and without (dashed line) header compression. The dotted lines show what MTU corresponds to a 200 ms packet time at 2400, 9600 and 19,200 bps. Note that with header compression even a 2400 bps line can be responsive yet have reasonable throughput (83%). Figure 9 shows how line efficiency scales with increasing line speed, assuming that a 200ms. MTU is always chosen.37 The knee in the performance curve is around 2400 bps. Below this, efficiency is sensitive to small changes in speed (or MTU since the two are linearly related) and good efficiency comes at the expense of good response. Above 2400bps the curve is flat and efficiency is relatively independent of speed or MTU. In other words, it is possible to have both good response and high line efficiency. To illustrate, note that for a 9600 bps line with header compression there is essentially no benefit in increasing the MTU beyond 200 bytes: If the MTU is increased to 576, the average delay increases by 188% while throughput only improves by 3% (from 96 to 99%).

Interaction with data compression
Since the early 1980’s, fast, effective, data compression algorithms such as Lempel-Ziv[7] and programs that embody them, such as the compress program shipped with Berkeley Unix, have become widely available. When using low speed or long-haul lines, it has become common practice to compress data before sending it. For dial-up connections, this compression is often done in the modems, independent of the communicating hosts. Some interesting issues would seem to be: (1) Given a good data compressor, is there any need for header compression? (2) Does header compression interact with data compression? (3) Should data be compressed before or after header compression?
To investigate (1), Lempel-Ziv compression was done on a trace of 446 TCP/IP packets taken from the user’s side of a typical telnet conversation. Since the packets resulted from typing, almost all contained only one data byte plus 40 bytes of header. I.e., the test essentially measured L-Z compression of TCP/IP headers. The compression ratio (the ratio of uncompressed to compressed data) was 2.6. In other words, the average header was reduced from 40 to 16 bytes. While this is good compression, it is far from the 5 bytes of header needed for good interactive response and far from the 3 bytes of header (a compression ratio of 13.3) that header compression yielded on the same packet trace.
The second and third questions are more complex. To investigate them, several packet traces from FTP file transfers were analyzed39 with and without header compression and with and without L-Z compression. The L-Z compression was tried at two places in the outgoing data stream (fig. 10): (1) just
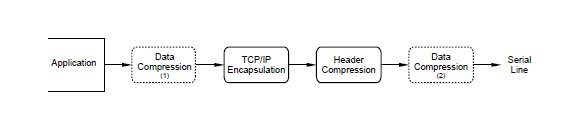
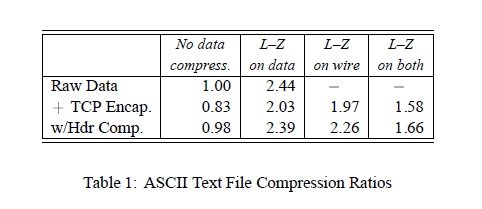
The first column of table 1 says the data expands by 19% (‘compresses’ by .83) when encapsulated in TCP/IP and by 2% when encapsulated in header compressed TCP/IP.
The first row says L–Z compression is quite effective on this data, shrinking it to less than half its original size. Column four illustrates the well-known fact that it is a mistake to L–Z compress already compressed data. The interesting information is in rows two and three of columns two and three. These columns say that the benefit of data compression overwhelms the cost of encapsulation, even for straight TCP/IP. They also say that it is slightly better to compress the data before encapsulating it rather than compressing at the framing/modem level. The differences, however, are small—3% and 6%, respectively, for the TCP/IP and header compressed encapsulations.
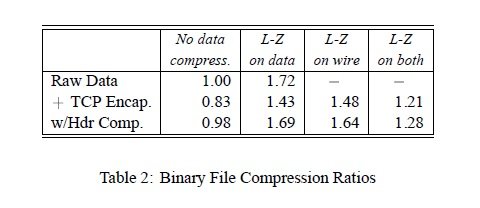
Table 2 shows the same experiment for a 122,880-byte binary file (the Sun-3 ps executable). Although the raw data doesn’t compress nearly as well, the results are qualitatively the same as for the ASCII data. The one significant change is in row two: It is about 3% better to compress the data in the modem rather than at the source if doing TCP/IP encapsulation (apparently, Sun binaries and TCP/IP headers have similar statistics). However, with header compression (row three) the results were similar to the ASCII data—it’s about 3% worse to compress at the modem rather than the source.
Performance measurements
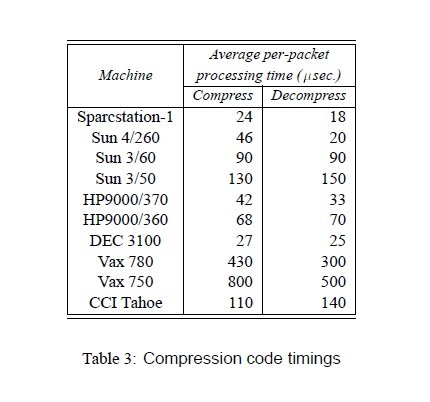
An implementation goal of compression code was to arrive at something simple enough to run at ISDN speeds (64Kbps) on a typical 1989 workstation. 64Kbps is a byte every 122_s so 120_s was (arbitrarily) picked as the target compression/decompression time.
As part of the compression code development, a trace-driven exerciser was developed. This was initially used to compare different compression protocol choices then later to test the code on different computer architectures and do regression tests after performance ‘improvements’. A small modification of this test program resulted in a useful measurement tool.45 Table 3 shows the result of timing the compression code on all the machines available to the author (times were measured using a mixed telnet/ftp traffic trace). With the exception of the Vax architectures, which suffer from (a) having bytes in the wrong order and (b) a lousy compiler (Unix pcc), all machines essentially met the 120_s goal.
 |  |  |  |  |  |
